IO多路转接(复用)之select

IO多路转接(复用)之select
苏丙榅1. IO多路转接(复用)
IO多路转接也称为IO多路复用,它是一种网络通信的手段(机制),通过这种方式可以同时监测多个文件描述符并且这个过程是阻塞的,一旦检测到有文件描述符就绪( 可以读数据或者可以写数据)程序的阻塞就会被解除,之后就可以基于这些(一个或多个)就绪的文件描述符进行通信了。通过这种方式在单线程/进程的场景下也可以在服务器端实现并发。常见的IO多路转接方式有:select、poll、epoll。
下面先对多线程/多进程并发和IO多路转接的并发处理流程进行对比(服务器端):
- 多线程/多进程并发
- 主线程/父进程:调用
accept()监测客户端连接请求- 如果没有新的客户端的连接请求,当前线程/进程会阻塞
- 如果有新的客户端连接请求解除阻塞,建立连接
- 子线程/子进程:和建立连接的客户端通信
- 调用
read() / recv()接收客户端发送的通信数据,如果没有通信数据,当前线程/进程会阻塞,数据到达之后阻塞自动解除 - 调用
write() / send()给客户端发送数据,如果写缓冲区已满,当前线程/进程会阻塞,否则将待发送数据写入写缓冲区中
- 调用
- 主线程/父进程:调用
- IO多路转接并发
- 使用IO多路转接函数委托内核检测服务器端所有的文件描述符(通信和监听两类),这个检测过程会导致进程/线程的阻塞,如果检测到已就绪的文件描述符阻塞解除,并将这些已就绪的文件描述符传出
- 根据类型对传出的所有已就绪文件描述符进行判断,并做出不同的处理
- 监听的文件描述符:和客户端建立连接
- 此时调用
accept()是不会导致程序阻塞的,因为监听的文件描述符是已就绪的(有新请求)
- 此时调用
- 通信的文件描述符:调用通信函数和已建立连接的客户端通信
- 调用
read() / recv()不会阻塞程序,因为通信的文件描述符是就绪的,读缓冲区内已有数据 - 调用
write() / send()不会阻塞程序,因为通信的文件描述符是就绪的,写缓冲区不满,可以往里面写数据
- 调用
- 监听的文件描述符:和客户端建立连接
- 对这些文件描述符继续进行下一轮的检测(循环往复。。。)
与多进程和多线程技术相比,I/O多路复用技术的最大优势是系统开销小,系统不必创建进程/线程,也不必维护这些进程/线程,从而大大减小了系统的开销。
2. select
2.1 函数原型
使用select这种IO多路转接方式需要调用一个同名函数select,这个函数是跨平台的,Linux、Mac、Windows都是支持的。程序猿通过调用这个函数可以委托内核帮助我们检测若干个文件描述符的状态,其实就是检测这些文件描述符对应的读写缓冲区的状态:
- 读缓冲区:检测里边有没有数据,如果有数据该缓冲区对应的文件描述符就绪
- 写缓冲区:检测写缓冲区是否可以写(有没有容量),如果有容量可以写,缓冲区对应的文件描述符就绪
- 读写异常:检测读写缓冲区是否有异常,如果有该缓冲区对应的文件描述符就绪
委托检测的文件描述符被遍历检测完毕之后,已就绪的这些满足条件的文件描述符会通过select()的参数分3个集合传出,程序猿得到这几个集合之后就可以分情况依次处理了。
下面来看一下这个函数的函数原型:
1 |
|
- 函数参数:
- nfds:委托内核检测的这三个集合中最大的文件描述符 + 1
- 内核需要线性遍历这些集合中的文件描述符,这个值是循环结束的条件
- 在Window中这个参数是无效的,指定为-1即可
- readfds:文件描述符的集合, 内核只检测这个集合中文件描述符对应的读缓冲区
传入传出参数,读集合一般情况下都是需要检测的,这样才知道通过哪个文件描述符接收数据
- writefds:文件描述符的集合, 内核只检测这个集合中文件描述符对应的写缓冲区
传入传出参数,如果不需要使用这个参数可以指定为NULL
- exceptfds:文件描述符的集合, 内核检测集合中文件描述符是否有异常状态
传入传出参数,如果不需要使用这个参数可以指定为NULL
- timeout:超时时长,用来强制解除select()函数的阻塞的
- NULL:函数检测不到就绪的文件描述符会一直阻塞。
- 等待固定时长(秒):函数检测不到就绪的文件描述符,在指定时长之后强制解除阻塞,函数返回0
- 不等待:函数不会阻塞,直接将该参数对应的结构体初始化为0即可。
- nfds:委托内核检测的这三个集合中最大的文件描述符 + 1
- 函数返回值:
- 大于0:成功,返回集合中已就绪的文件描述符的总个数
- 等于-1:函数调用失败
- 等于0:超时,没有检测到就绪的文件描述符
另外初始化fd_set类型的参数还需要使用相关的一些列操作函数,具体如下:
1 | // 将文件描述符fd从set集合中删除 == 将fd对应的标志位设置为0 |
2.2 细节描述
在select()函数中第2、3、4个参数都是fd_set类型,它表示一个文件描述符的集合,类似于信号集 sigset_t,这个类型的数据有128个字节,也就是1024个标志位,和内核中文件描述符表中的文件描述符个数是一样的。
1 | sizeof(fd_set) = 128 字节 * 8 = 1024 bit // int [32] |
这并不是巧合,而是故意为之。这块内存中的每一个bit 和 文件描述符表中的每一个文件描述符是一一对应的关系,这样就可以使用最小的存储空间将要表达的意思描述出来了。
下图中的fd_set中存储了要委托内核检测读缓冲区的文件描述符集合。
- 如果集合中的标志位为
0代表不检测这个文件描述符状态 - 如果集合中的标志位为
1代表检测这个文件描述符状态

内核在遍历这个读集合的过程中,如果被检测的文件描述符对应的读缓冲区中没有数据,内核将修改这个文件描述符在读集合fd_set中对应的标志位,改为0,如果有数据那么这个标志位的值不变,还是1。

当select()函数解除阻塞之后,被内核修改过的读集合通过参数传出,此时集合中只要标志位的值为1,那么它对应的文件描述符肯定是就绪的,我们就可以基于这个文件描述符和客户端建立新连接或者通信了。
3. 并发处理
3.1 处理流程
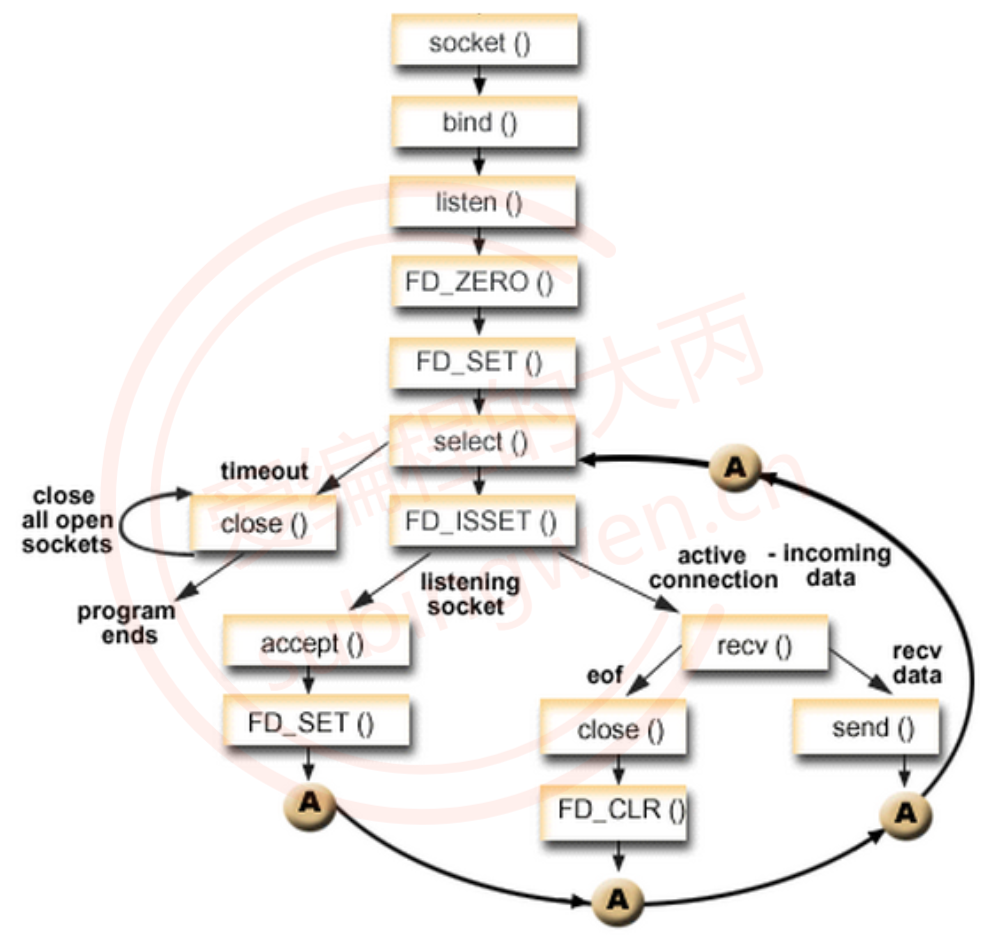
如果在服务器基于select实现并发,其处理流程如下:
- 创建监听的套接字 lfd = socket();
- 将监听的套接字和本地的IP和端口绑定 bind()
- 给监听的套接字设置监听 listen()
- 创建一个文件描述符集合 fd_set,用于存储需要检测读事件的所有的文件描述符
- 通过 FD_ZERO() 初始化
- 通过 FD_SET() 将监听的文件描述符放入检测的读集合中
- 循环调用select(),周期性的对所有的文件描述符进行检测
- select() 解除阻塞返回,得到内核传出的满足条件的就绪的文件描述符集合
- 通过FD_ISSET() 判断集合中的标志位是否为 1
- 如果这个文件描述符是监听的文件描述符,调用 accept() 和客户端建立连接
- 将得到的新的通信的文件描述符,通过FD_SET() 放入到检测集合中
- 如果这个文件描述符是通信的文件描述符,调用通信函数和客户端通信
- 如果客户端和服务器断开了连接,使用FD_CLR()将这个文件描述符从检测集合中删除
- 如果没有断开连接,正常通信即可
- 如果这个文件描述符是监听的文件描述符,调用 accept() 和客户端建立连接
- 通过FD_ISSET() 判断集合中的标志位是否为 1
- 重复第6步
3.2 通信代码
服务器端代码如下:
1 |
|
在上面的代码中,创建了两个
fd_set变量,用于保存要检测的读集合:
1 | // 初始化检测的读集合 |
rdset用于保存要检测的原始数据,这个变量不能作为参数传递给select函数,因为在函数内部这个变量中的值会被内核修改,函数调用完毕返回之后,里边就不是原始数据了,大部分情况下是值为1的标志位变少了,不可能每一轮检测,所有的文件描述符都是就行的状态。因此需要通过rdtemp变量将原始数据传递给内核,select() 调用完毕之后再将内核数据传出,这两个变量的功能是不一样的。
客户端代码:
1 |
|
客户端不需要使用IO多路转接进行处理,因为客户端和服务器的对应关系是 1:N,也就是说客户端是比较专一的,只能和一个连接成功的服务器通信。
虽然使用select这种IO多路转接技术可以降低系统开销,提高程序效率,但是它也有局限性:
- 待检测集合(第2、3、4个参数)需要频繁的在用户区和内核区之间进行数据的拷贝,效率低
- 内核对于select传递进来的待检测集合的检测方式是线性的
- 如果集合内待检测的文件描述符很多,检测效率会比较低
- 如果集合内待检测的文件描述符相对较少,检测效率会比较高
使用select能够检测的最大文件描述符个数有上限,默认是1024,这是在内核中被写死了的。






















