Qt 多线程之 QtConCurrent

Qt 多线程之 QtConCurrent
苏丙榅1. QtConcurrent 类概述
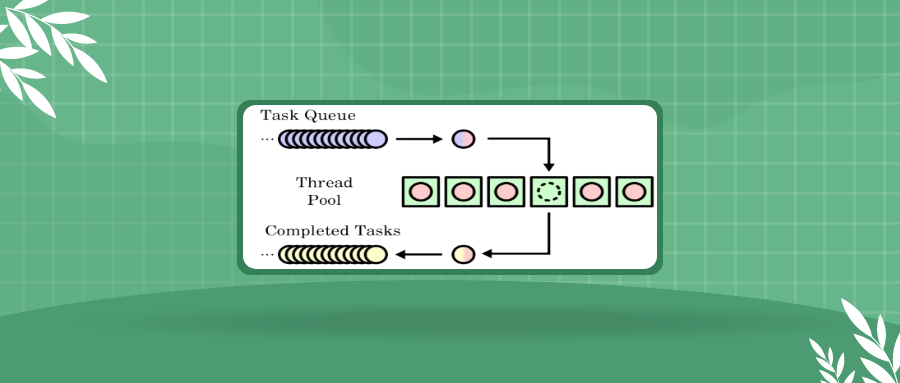
QtConcurrent 是 Qt 提供的高级 API,位于 QtConcurrent 命名空间下。它是对 QThreadPool 和 QFuture 的高级封装,旨在简化多线程编程。
QtConcurrent模块默认情况下并不自己创建线程,而是复用QThreadPool::globalInstance()。- 异步执行:任务被扔到线程池后,主线程立即返回,继续执行后续代码。
QFuture代表了未来的结果,包括:状态查询,进度反馈,结果传递。
它的最大优势是:你不需要手动创建和管理线程,也不需要处理线程底层的同步逻辑,只需关注要执行的函数。它把怎么开启线程、怎么分配任务给哪个线程、怎么回收线程这些脏活累活都交给了 QThreadPool,只留给你 QFuture 作为接口,让你专注于做什么而不是怎么做。
1.1 准备工作
在使用 QtConcurrent 之前,必须在项目文件(.pro 或 CMakeLists.txt)中引入 concurrent 模块:
.pro (qmake):
1 | QT += core concurrent |
CMakeLists.txt: (以 Qt6 为例,Qt5 亦如此,修改版本号即可)
1 | find_package(Qt6 REQUIRED COMPONENTS Core Concurrent) |
头文件引入:
1 |
1.2 QFuture 与 QFutureWatcher
1.2.1 QFuture 静默的结果搬运工
通俗地说,QFuture 就是一张提货单。当你下单一个异步任务(比如 “计算文件夹 SHA1”)时,商店(Qt 系统)不会立刻给你货(计算结果),因为货还在做。商店给你的就是这张 QFuture 提货单。你拿着这张单子,虽然还没拿到货,但你可以随时询问商店:“我的货好了没?”
具体能力(它能干什么?)
作为数据的容器,它主要提供了以下 API 栈:
查询状态:
isFinished(),isRunning(),isCanceled(),可以在代码里随时检查:1
2
3
4// 函数原型, 条件成立返回 true, 否则返回 false
bool QFuture::isFinished() const;
bool QFuture::isRunning() const;
bool QFuture::isCanceled() const;1
2
3
4if (future.isFinished())
{
// 好了,可以拿东西了
}获取结果:
result(),resultAt(i),results()1
2
3
4
5
6
7// 函数原型
template <typename U = T, typename = QtPrivate::EnableForNonVoid<U>>
T QFuture::result() const;
template <typename U = T, typename = QtPrivate::EnableForNonVoid<U>>
T QFuture::resultAt(int index) const;
template <typename U = T, typename = QtPrivate::EnableForNonVoid<U>>
QList<T> QFuture::results() const;- 如果任务只返回一个
T 类型的值(比如:QString),用future.result()。 - 如果任务返回一堆值(
mapped中的QList<T>),用future.resultAt(0)拿第一个。 - 如果在主线程调用以上这些
result()函数,但是计算还没做完,主线程会阻塞(卡死)直到结果出来。
- 如果任务只返回一个
控制任务:
cancel(),waitForFinished()1
2
3// 函数原型
void QFuture::cancel();
void QFuture::waitForFinished();cancel():在提货单上盖个“作废”章,告诉后台别做了。waitForFinished():你不想走了,就在商店门口一直等,直到货出来(这会阻塞当前线程)。
本质限制(为什么它不够用?)
QFuture 是一个轻量级的值类型(像 int 一样),它没有继承 QObject。这意味着:
- 它没有父对象,无法被 Qt 的对象树自动管理。
- 它不能发射信号(Signal/Slot)。
- 它不知道自己依附于哪个线程。
结论:QFuture 很适合纯逻辑层的数据传递,但它无法“主动”告诉主界面“我好了”。你必须用轮询或者死等的方式去问它,这在 GUI 编程中很不方便。
1.2.2 QFutureWatcher:大嗓门的观察员
QFutureWatcher 的作用就是盯着 QFuture,一旦有动静,立刻通过信号槽大叫出来通知 UI。
具体工作原理(它是如何配合的?)
如果把 QFuture 比作“监控摄像头画面的原始数据流”,那么 QFutureWatcher 就是“连着摄像头的显示器”。
建立连接:
你需要把一个QFuture喂给QFutureWatcher:1
2
3
4// 构造函数
QFutureWatcher::QFutureWatcher(QObject *parent = nullptr);
// 将 QFuture 对象设置给 QFutureWatcher
void QFutureWatcher::setFuture(const QFuture<T> &future);1
2QFutureWatcher<QString> watcher;
watcher.setFuture(future); // Watcher 开始盯着这个 Future信号转化(核心):
QFutureWatcher继承自QObject,所以它拥有信号槽能力。它在后台默默监控QFuture的内部状态变化,一旦检测到变化,就发射对应的信号:1
2
3
4[signal] void QFutureWatcher::canceled();
[signal] void QFutureWatcher::finished();
[signal] void QFutureWatcher::resultReadyAt(int index);
[signal] void QFutureWatcher::progressValueChanged(int progressValue);- 内部产生了一个结果:发射
resultReadyAt(int index)信号。 - 内部整体做完了:发射
finished()信号。 - 内部更新了进度:发射
progressValueChanged(int value)信号。 - 内部被取消了:发射
canceled()信号。
- 内部产生了一个结果:发射
绑定 UI:
因为它能发射信号,你就可以用 Qt 最擅长的槽函数机制来响应:1
2
3
4// 当 Watcher 喊“第 3 个文件算完了”,UI 就更新第 3 行
connect(&watcher, &QFutureWatcher<QString>::resultReadyAt, this, [](int index){
ui->tableWidget->setItem(index, 0, new QTableWidgetItem("完成"));
});
为什么 GUI 程序必须用它?
因为GUI 是事件驱动的。
- 没有 Watcher 时:你的主线程必须在一个
while循环里不断问future.isFinished()。这是一种“轮询”模式,极其浪费 CPU,而且代码写起来很丑。 - 有了 Watcher:你就可以放手不管了。后台线程算完一个,Watcher 会自动把一个事件投递到主线程的消息队列里。主线程此时正在处理界面绘制,等它空闲了,自然会发现这个事件,从而触发你的槽函数。这种方式不卡界面,也不会漏掉消息。
1.2.3 总结
举个生动的例子:外卖点餐
QFuture(外卖单):- 手机 APP 上的订单页面。
- 你可以不断刷新它看状态是“制作中”还是“配送中”(
isRunning)。 - 但如果你不刷新,它不会主动跳出来告诉你饭好了。
- 如果你不刷新,只是一直盯着屏幕等,你什么也别想干了(
waitForFinished阻塞)。
QFutureWatcher(外卖员电话):- 它是连接商家(后台线程)和你(主线程)的桥梁。
- 虽然商家在跑腿,但你不用一直刷新 APP。
- 当饭做好了(
resultReady),你会接到电话:“你好,你的饭到了”。 - 你接起电话(
slot),然后去拿饭(更新 UI)。
| 特性 | QFuture |
QFutureWatcher |
|---|---|---|
| 身份 | 数据容器 | 监控器 / 适配器 |
| 继承关系 | 纯 C++ 类 | 继承自 QObject |
| 能力 | 存结果、查状态、取消任务 | 发射信号、暂停/继续、连接 UI |
| 使用场景 | 后台纯逻辑处理、函数间传递结果 | GUI 界面更新、多线程交互 |
| 依存关系 | 可以独立存在 | 必须 setFuture() 才能工作 |
一句话总结:QFuture 负责在后台干活和存数据,QFutureWatcher 负责在前台喊话和传信。
2. 常用 API 详解与举例
QtConcurrent 提供了三个最核心的功能:运行单个函数、并发处理序列、并发规约。
2.1 运行单个函数 (QtConcurrent::run)
这是最常用的方式,用于在另一个线程中运行一个函数或成员方法。
1 | template <typename T> |
QThreadPool *pool:指定一个自定义的线程池,用来运行指定的任务。Function function: 指定在子线程中执行的函数(或者可调用对象)可以是全局函数、静态成员函数、
std::function,也可以是Lambda 表达式。...可变参数:传递给上面那个function的实参。Qt 会将这些参数拷贝一份,传递给新线程去执行。
场景:后台执行耗时计算。
A. 运行普通函数
1 | // 定义一个耗时函数 |
B. 运行类的成员函数
需要注意,类对象在线程中的生命周期。建议使用 const 引用或指针,防止拷贝。
1 | class DataProcessor : public QObject { |
2.2 并发修改序列 (QtConcurrent::map)
对序列(如 QList)中的每一项应用一个函数。该函数直接修改原始项(引用传递),没有返回值。
1 | template <typename Sequence, typename MapFunctor> |
- 这两个参数的作用是告诉
map函数,你需要对哪一份数据进行修改。出现了两种形式:Sequence &&sequence(容器整体)- 含义:直接传入一个容器对象。
- 支持类型:通常是
QList、QVector、std::vector等 STL 或 Qt 容器。 - 用法:把整个
list传进去,map会自动把它拆开分发给每个线程。 T&&(未定引用类型(万能引用类型)):意味着它可以接受临时对象,当然也可以接受普通对象。因此,该参数可用是左值也可以是右值。
Iterator begin, Iterator end(迭代器范围)- 含义:传入一个“半开区间”
[begin, end),表示从哪里开始处理,到哪里结束(不包含 end)。 - 支持类型:任何符合 STL 标准的迭代器(比如
vector.begin())。 - 用法:这比传容器更灵活。比如你只想修改
QList的前 5 个元素,就可以传list.begin()和list.begin() + 5。
- 含义:传入一个“半开区间”
- 操作参数(要做什么?):
MapFunctor &&function- 含义:这是一个函数(或 Lambda 表达式),也就是要对每个元素执行的“操作”。
- 特征:这个函数必须有且仅有一个参数。
- 参数类型:这个参数的类型必须是容器元素的引用(例如
int&或QString&),或者是可以修改对象的类型。 - 为什么是引用?因为
map 函数的目的是“原地修改”。- 如果你的函数是
void func(int x) { x = 10; },那么修改无效(改的是副本)。 - 必须是
void func(int &x) { x = 10; },这样容器里的值才会真的发生改变。
- 如果你的函数是
- 环境参数(在哪里执行?- 可选):
QThreadPool *pool- 含义:指定运行任务的线程池。
- 作用:如果你不传这个参数(用前两个函数),任务会扔到 Qt 的全局线程池。如果传了这个参数,任务会在指定的线程池里执行。
场景:批量修改图片的属性信息。
1 | struct Image { |
2.3 并发处理并保留结果 (QtConcurrent::mapped)
与 map 类似,但操作函数不修改原项,而是返回一个新值。mapped 会生成一个新的 QList。
1 | template <typename Sequence, typename MapFunctor> |
这四个函数是 QtConcurrent::mapped 的重载形式。相较于QtConcurrent::map函数二者区别为:
map:原地修改容器。mapped:映射生成新数据,容器中的数据不变。
QtConcurrent::mapped 的大部分参数含义与 QtConcurrent::map 相同。
Sequence &&sequence(容器整体)- 含义:传入整个容器(如
QList,QVector,std::vector)。 - 行为:函数会读取这个容器中的每一个元素。注意:原容器不会发生任何变化。
- 含义:传入整个容器(如
Iterator begin, Iterator end(迭代器范围)- 含义:传入起始和结束迭代器(半开区间
[begin, end))。 - 行为:处理该范围内的所有元素。同样,迭代器指向的数据是只读的(除非你强制转换,但不推荐)
- 含义:传入起始和结束迭代器(半开区间
MapFunctor &&function- 含义:转换函数。输入“旧元素”,输出“新元素”。
- 对该函数的要求:
- 它接受一个参数(即容器中的元素类型)。
- 它返回一个值(即转换后的结果类型)。
- 关键点(与
map的核心区别):- 参数不需要是引用,因为它只是读取数据。
- 例如:
int square(int x) { return x * x; }。输入 2,返回 4。
QThreadPool *pool:指定线程池。如果不传,则使用全局线程池。
返回值类型(模板部分的解释),你可能会注意到返回值写得很复杂:
1 | QFuture<QtPrivate::MapResultType<Sequence, MapFunctor>> |
QFuture<...>:- 因为计算是异步的,所以返回一个
QFuture对象。 - 可以通过
future.results()获取最终计算出来的新容器。
- 因为计算是异步的,所以返回一个
QtPrivate::MapResultType<...>:- 这是一个 Qt 内部的类型推导魔法。
- 它的意思是:根据提供的输入容器类型和函数返回值类型,自动推断出最终的容器类型。
- 举例:
- 如果输入
QList<int>,函数返回int,结果就是QList<int>。 - 如果输入
QList<int>,函数返回QString,结果就是QList<QString>。 - 如果输入
std::vector<double>,函数返回int,结果就是std::vector<int>。
- 如果输入
场景:读取一堆文件内容,并对数据进行计算。
1 | // 翻倍函数:参数是 const,返回新值 |
2.4 并发归约 (QtConcurrent::mappedReduced)
这是 Map-Reduce 模式的实现。先并发处理每一项,然后将所有结果处理并最终合并成一个结果。
1 | template <typename ResultType, typename Sequence, typename MapFunctor, typename ReduceFunctor> |
QtConcurrent::mappedReduced 是 QtConcurrent 中最强大、最灵活的函数之一。它的核心思想是 Map-Reduce(映射-归约) 模式:
- Map:把一堆输入数据,转换成中间结果。
- Reduce:把所有的中间结果,合并(汇总)成最终的一个结果。
这在处理求和、统计、拼接字符串等需要将大量数据合并为一个值的任务时非常有用。
下面详细解释参数和返回值。
2.4.1 参数详解
我们可以将参数分为五类来理解:
A. 结果类型(显式指定)
template <typename ResultType>
- 含义:这是模板参数(不是函数调用参数),写在尖括号里。
- 作用:你必须明确告诉 Qt,最终算出来的结果是什么类型。
- 示例:如果要算所有数字的和,这里就是
int或double;如果要把所有字符串拼起来,这里就是QString。
B. 原始数据(输入端)
这组参数与 map/mapped 完全一样,用于提供原材料(原始数据)。
Sequence &&sequence:整个容器。Iterator begin, Iterator end:迭代器范围。
C. Map 函数(变换逻辑:怎么做第一步)
MapFunctor &&mapFunction- 含义:用于处理容器中每一个元素的函数。
- 输入:容器中的一个元素。
- 输出:一个中间结果(这个中间结果稍后会被
Reduce函数处理)。 - 注意:不要在这里修改原容器,这里是做转换的。
D. Reduce 函数(合并逻辑:怎么做第二步)
ReduceFunctor &&reduceFunction含义:将 Map 产生的“中间结果”合并到“最终结果”中的函数。
对该函数的要求:
1
void reduce(T &result, const U &intermediate);
- 第一个参数
result:这是累积结果的引用(比如当前的累加和)。函数会直接修改这个值。 - 第二个参数
intermediate:这是 Map 函数刚刚吐出来的中间结果(只读)。
- 第一个参数
示例:
1
2
3
4// 1. 如果是求和:
void reduce(int &sum, int value) { sum += value; };
// 2. 如果是拼字符串:
void reduce(QString &str, const QString &part) { str += part; };
E. 初始值(可选)
InitialValueType &&initialValue- 含义:在开始 Reduce 之前,那个“累积结果”(即上面 Reduce 函数的第一个参数)的初始值是什么。
- 作用:如果不传这个参数,Qt 会使用
ResultType的默认构造函数初始化(比如int默认是 0,QString默认是空)。 - 场景:如果你想求和,但希望初始值是 100 而不是 0,就可以传这个。
F. 线程池(可选)
QThreadPool *pool- 位置:参数列表的最前面。
- 作用:指定在哪个线程池运行,不传则用全局默认池。
G. 归约选项(可选,默认存在)
QtConcurrent::ReduceOptions reduceOptions默认值:
UnorderedReduce | SequentialReduce作用:控制 Reduce 的顺序和行为。
常用值:
OrderedReduce:保证最终结果按原始顺序组合(通常慢一些)。UnorderedReduce:不保证顺序(通常快一些)。SequentialReduce:强制按顺序一个一个归约(无法利用多核并行归约)。
2.4.2 返回值详解
QFuture<ResultType>- 含义:一个代表“未来计算结果”的对象。
ResultType:这就是在模板参数里指定的那个最终结果的类型。- 用法举例:通过
future.result()获取最终汇总后的那一个值。
场景:处理多个独立字符串,并拼接所有字符串。
1 | // Map 函数:处理单个项,返回中间结果 |
2.5 限制线程数与取消任务
限制线程数
QtConcurrent 默认使用全局线程池(QThreadPool::globalInstance()),默认线程数通常等于 CPU 核心数。如果你想限制并发线程数,可以使用 QThreadPool。
1 | // 创建一个自定义的池子,限制最大线程数为 2 |
取消任务
QFuture 提供了 cancel() 方法。注意,cancel 并不是强制杀死线程(强制杀死线程在 C++ 中很危险且不推荐),它只是设置一个标志位,指示跳过尚未开始的任务。
1 | // 假设有一个非常长的列表 |
2.6 注意事项
- 共享数据的互斥:
QtConcurrent虽然方便,但它只是帮你把函数扔到了不同线程。如果多个并发函数同时读写同一个全局变量或共享对象,你依然需要使用QMutex或QReadWriteLock进行保护。 - UI 操作警告:与所有多线程一样,严禁在
QtConcurrent::run执行的函数中直接操作 UI(如setText)。请通过信号槽转发回主线程。 - QObject 子线程问题:不要试图将
QObject派生类的移动传递给QtConcurrent,QtConcurrent适用于函数式编程模型,而不是对象生命周期管理。 - 异常处理:如果在
QtConcurrent执行的函数中抛出了异常,该异常会被 Qt 捕获并存储在QFuture中。主线程通过future.result()时,异常会在主线程重新抛出(或者在 Qt 6 中通过future.isCanceled()等状态判断)。建议尽量使用返回值(如boolsuccess)来通知错误,而不是抛出异常。
2.7. 案例:批量文件处理
假设我们要做一个功能:计算一堆大文件的 MD5 值(非常耗时),并在进度条显示或列表显示结果。
1 |
|
通过 QtConcurrent::mapped + QFutureWatcher,你只需要几行代码就实现了高性能的多线程文件处理,并且完美避开了手动管理线程的麻烦。