字典树

字典树
苏丙榅1. Trie 树的基本概念
Trie树,又称字典树、前缀树,是一种树形数据结构,常用于高效地存储和检索字符串集合。它的主要特点是利用字符串的公共前缀来减少存储空间和提高查询效率,特别适用于字符串的前缀匹配、自动补全、拼写检查等场景。
对于一棵字典树而言具有以下基本性质:
- 它是一棵多叉树,每个节点代表一个字符。根节点不包含字符,除根节点外的每个节点都包含一个字符。
- 从根节点到某一节点的路径上经过的字符连接起来,即为该节点对应的字符串。
- 每个节点可能有多个子节点,每个子节点对应一个不同的字符。
- 通常在表示字符串集合的Trie树中,会有一些特殊标记来表示某个节点是否是一个字符串的结尾。
下图是一颗字典树,在树中存储了这些单词:
app、apple、acc、acce、access、back、backup、backed、be、bea、bearca、can、cancel、cancer、car、carbon、cause
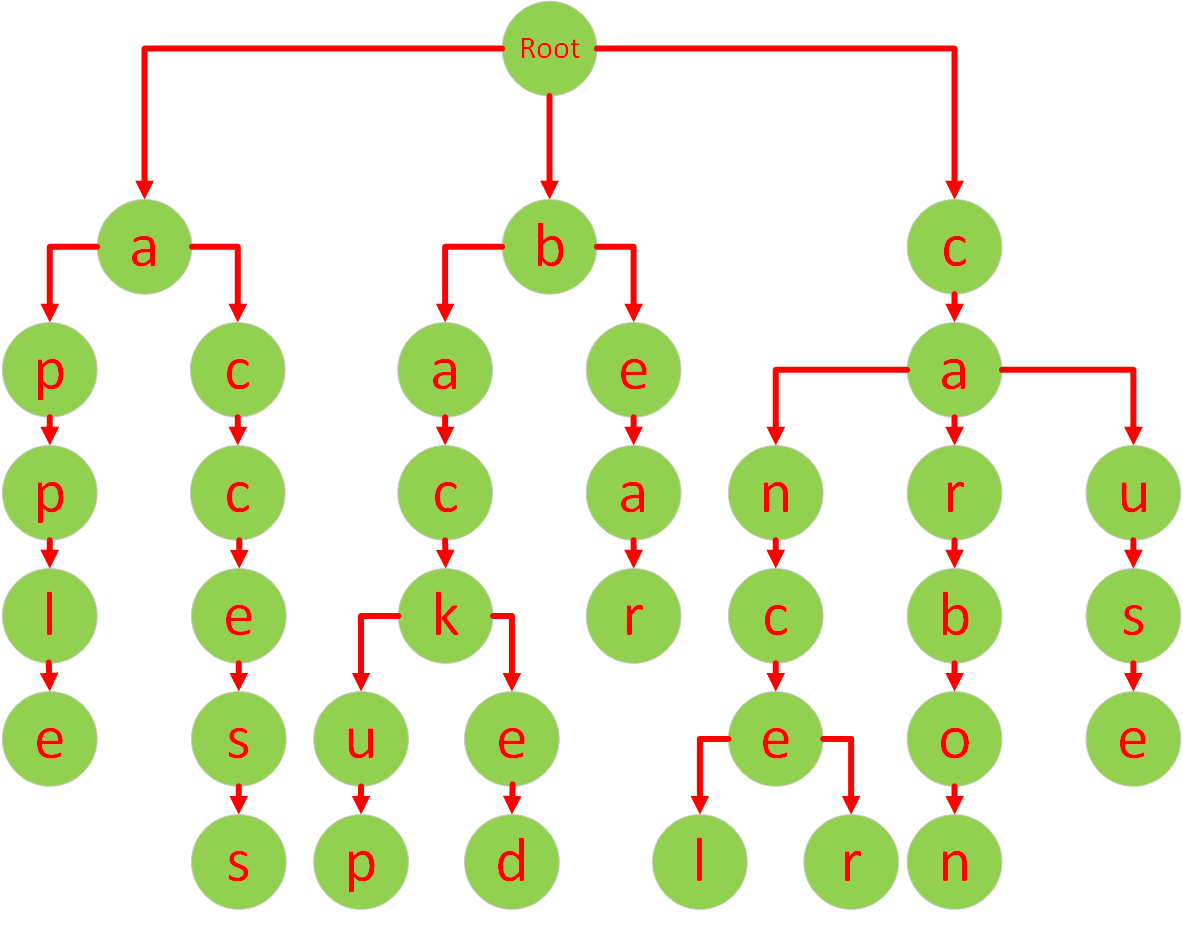
基于字典树的特性,我们可以得知它是天然支持前缀匹配的,因为字典树可以适用于以下的场景:
字符串检索
可以高效地查找某个字符串是否存在于一个字符串集合中,时间复杂度为
O(m),其中m是字符串的长度。与字典树中存储的字符串数量无关,因此在处理大量字符串时检索效率极高。自动补全
在搜索引擎、输入法等应用中,根据用户输入的前缀,快速找到以该前缀开头的所有字符串,提供自动补全功能。
拼写检查
借助字典树的快速前缀匹配能力,能够高效地对大量文本中的单词进行拼写检查,无需对每个可能的正确单词进行逐个比较,大大提高了检查效率。
词频统计
字典树可以在插入单词的同时完成词频统计,避免了额外的排序和统计操作,并且利用前缀共享的特性节省了存储空间,提高了统计效率。
IP路由
在大规模网络中,存在大量的路由条目,使用字典树进行最长前缀匹配的效率比传统的线性查找方法要高得多,能够快速准确地为数据包找到合适的路由,减少网络延迟。
由此可见字典树的优点是非常明显的,但是它并不是完美的,下面为大家总结了它的优缺点:
- 优点
- 高效的前缀匹配:可以在
O(m)的时间复杂度内完成字符串的插入、查找和删除操作。 - 节省空间:通过共享公共前缀,减少了存储空间的使用。
- 高效的前缀匹配:可以在
- 缺点
- 空间开销较大:每个节点需要存储多个指针,对于大规模的字符集,空间开销会比较大。
字典树作为一种经典的数据结构,是空间换时间这一数据处理策略的典型代表。它以适当增加存储空间为代价,显著提升了字符串检索、插入和删除等操作的执行效率。
2. Trie树的定义
2.1 Trie树节点
字典树,作为一种高效的数据结构,其节点具备多样化且关键的功能。具体而言,字典树的节点主要承担着三项核心任务:
- 它能够精准地存储字符信息,这些字符是构建字符串的基本元素,通过节点对字符的存储,使得字典树可以对字符串集合进行有效的组织和管理。
- 节点会记录以从根节点到该节点所形成的字符串为前缀的单词出现频率。若此字符串本身就是一个完整的单词,那么该频率值就代表了这个单词在集合中的出现次数,这为后续的词频统计等操作提供了便利。
- 节点会存储其所有子节点的信息,这是构建字典树树形结构的基础,通过子节点的关联,形成了丰富的字符串路径。
鉴于字典树本质上是一棵多叉树,其每个节点可能存在多个子节点。为了高效地存储和管理这些子节点,我们可以巧妙地运用映射关系来实现。映射关系能够建立起字符与子节点之间的一一对应,使得在查找、插入或删除子节点时,能够快速定位到目标节点,大大提高了操作的效率。
因此,我们可以这样定义这棵字典树的树节点:
1 | struct TrieNode |
ch:用于存储当前节点所代表的字符。例如在构建存储单词的字典树时,这个字符就是单词中的某个字母。freq:表示以从根节点到当前节点所形成的字符串为前缀的单词的出现频率。children:用于添加和查找子节点。当需要插入一个新的字符时,可以在children中查找是否已经存在对应的子节点,如果存在则直接使用该子节点;如果不存在则创建一个新的子节点并插入到children中。
2.2 Trie树类
接下来,为了能高效且系统地实现字典树的各项功能,我们将定义一个专门的字典树类。此字典树类会把字典树的核心功能封装起来,通过合理设计成员变量和成员函数,构建一个完整且易于管理与使用的代码结构。
在这个类的实现过程中,我们将涵盖诸如插入单词、删除单词、查询单词是否存在、统计单词频率以及进行前缀搜索等常见且关键的操作,以此来充分发挥字典树在字符串处理方面的优势,实现对字符串集合的高效存储和快速检索。
1 | class TrieTree |
m_root:这是一个指向TrieNode类型的指针,代表字典树的根节点。所有的操作都是从这个根节点开始的。TrieTree():构造函数,用于初始化字典树。通常在这个函数中,会创建一个根节点,并将m_root指针指向它。~TrieTree():析构函数,用于释放字典树占用的内存。它会调用deleteNodes函数递归地释放所有节点。void add(const string& word):将一个单词插入到字典树中。void remove(const string& word):从字典树中删除一个单词。int query(const string& word):查询一个单词是否存在于字典树中,如果存在则返回其出现的次数,否则返回 0。vector<string> queryPrefix(const string& prefix);:查找所有以给定前缀开头的单词。deleteNodes(TrieNode* node):用递归的方式释放以node为根的子树中的所有节点。void preOrder():对字典树进行前序遍历,并输出所有的单词。preOrder(TrieNode* cur, string& word, vector<string>& wordlist):前序遍历的辅助函数,用于递归地遍历字典树,并将遍历到的单词添加到wordlist中。
3. Trie树的实现
3.1 构造和析构
释放多叉树节点的操作与二叉树有着异曲同工之妙。二者均遵循后序遍历的思想,也就是先对各个子节点进行销毁操作,最后再销毁根节点。示例代码如下:
1 | TrieTree::TrieTree() : m_root(new TrieNode('\0', 0)) |
以当前这棵字典树为例,从根节点开始调用 deleteNodes 函数,在处理每个节点时,会先深入到其所有子节点所在的子树,递归地执行子节点的销毁步骤,待该节点下的所有子节点都被妥善销毁后,才会将此节点本身销毁。
通过不断重复这样的操作,从最底层的叶子节点开始,逐层向上进行节点销毁,逐步缩小树的规模,直至根节点被销毁,至此整个多叉树便完成了销毁过程。这样的销毁方式能够确保在释放内存时不会出现遗漏,避免因部分节点未被正确释放而造成内存泄漏的问题,保障了系统资源的合理使用和程序运行的稳定性。
3.2 添加数据
添加一个单词到字典树中,需要遍历该单词的每个字符,并根据字符在字典树中找到或创建相应的节点。具体步骤如下:
- 从根节点开始:让遍历字典树的辅助指针(当前节点指针)指向根节点。
- 遍历单词的每个字符:检查当前节点存储子节点的映射中是否存在该字符对应的子节点。
- 如果存在:更新当前节点指针,让它指向该子节点。
- 如果不存在:创建一个新的节点,并将其保存到当前节点的映射表中。然后让遍历字典树的当前节点指针指向这个新节点。
- 标记单词结尾:当遍历完单词的所有字符后,将当前节点的
freq加1。
以下是实现添加节点功能的 C++ 代码:
1 | void TrieTree::add(const string& word) |
current->children[ch] = new TrieNode(ch, 0); 这行代码是往 current 对象的 children 这个 std::map里添加了一条新的数据。
- 如果
ch键不存在:std::map会创建一个新的键值对,键为ch,值为新创建的TrieNode对象的指针。 - 如果
ch键已经存在:std::map会更新这个键对应的值,将原来的值替换为新创建的TrieNode对象的指针(在代码中不存在数据替换的情况)。
3.3 删除数据
在字典树中删除节点时,需要考虑多种不同的情况,具体如下:
要删除的单词在字典树中不存在
如果要删除的单词在字典树中根本不存在,那么无需进行任何删除操作,直接返回原字典树的根节点。
要删除的单词是其它单词的前缀
当要删除的单词是其它单词的前缀时,只需将该节点的
freq设置为0即可,不需要删除该节点及其子节点。例如,字典树中有apple和app,若要删除app,则只需将app对应的节点的freq设为0,apple仍然保留。要删除的单词和其它单词有公共前缀
若要删除的单词和其它单词有公共前缀,该路径上的公共前缀需要保留,删除公共前缀之后的部分即可。例如,字典树中有
app和apple,若要删除apple,app仍然会保留。要删除的单词没有其他依赖(即路径上无其他单词使用该路径)
当要删除的单词没有其它依赖时,从该单词的最后一个字符节点开始,逐步回溯删除没有其它子节点且不是其他单词结尾的节点。
以下是实现删除节点功能的 C++ 代码:
1 | void TrieTree::remove(const string& word) |
删除操作函数的remove(TrieNode* root, const string& word, int depth)的主要逻辑:
基本情况:
- 如果
root为空,返回nullptr,表示当前节点不存在。 - 如果
depth等于单词长度,表示已经处理到单词的最后一个字符:- 如果当前节点的
freq大于零,说明这是一个单词的结尾,将freq置为零。 - 如果当前节点没有子节点,说明它不再有用,删除该节点并返回
nullptr。
- 如果当前节点的
- 如果
递归下降:从根节点开始,逐层处理单词的每个字符,直到到达单词的最后一个字符。
处理最后一个字符节点:
- 将
freq置为零,表示该节点不再是一个单词的结尾。 - 如果该节点没有子节点,删除该节点。
- 将
回溯处理:在回溯过程中,检查每个节点是否需要删除。如果一个节点没有子节点且
freq小于一,说明它不再有用,可以删除。
3.4 前缀搜索
前序遍历字典树
在进行前缀搜索时,其重要前提是对字典树开展前序遍历操作。前序遍历作为一种基础且关键的树遍历方式,能按照特定顺序依次访问字典树的各个节点。
在字典树的结构里,前序遍历从根节点开始,首先访问根节点,接着递归地访问其各个子节点。通过这种方式,能系统性地扫描字典树中的所有路径,为前缀搜索奠定坚实基础。在搜索特定前缀时,前序遍历能引导程序快速定位到包含该前缀的路径,进而高效地筛选出符合前缀要求的所有词汇或数据,极大地提高搜索效率和准确性。
1 | void TrieTree::preOrder() |
该函数通过前序遍历的方式递归地遍历字典树的所有节点,在遍历过程中动态构建字符串,并将有效的单词收集到 wordlist 向量中。回溯时,通过word.pop_back()操作确保了 word 字符串在递归调用之间的状态正确,避免了不同路径之间的干扰。最终,wordlist 向量将包含字典树中存储的所有有效单词。
前缀搜索
若要实现前缀搜索功能,可编写如下函数:此函数接收一个字符串作为待查询的前缀,于前缀树这一高效的数据结构中精准搜索所有与该前缀相匹配的单词。搜索完成后,把这些匹配到的单词存储在一个字符串数组中并返回,从而为进一步的数据处理或展示提供便利。
1 | vector<string> TrieTree::queryPrefix(const string& prefix) |
在基于提供的前缀进行字符串搜索时,需要先提供一个word对象:
1 | string word(prefix, 0, prefix.size() - 1); |
创建一个字符串 word,其内容为前缀 prefix 去掉最后一个字符后的部分。这是因为在后续调用 preOrder 函数时,会将当前节点的字符添加到 word 中,为了避免重复添加前缀的最后一个字符,这里先去掉它。
接下来就可以基于这个wrod进行前序遍历,最后将所有满足条件的单词以返回值的方式给到函数调用者。
完全搜索
除了前缀搜索以外,我们还可以根据某个完整的单词在树结构中进行精确查找。这种精确搜索方式能够迅速判断该单词是否存在于字典树中,为需要严格匹配的应用场景,如拼写检查、词汇验证等,提供了高效且可靠的解决方案。
1 | int TrieTree::query(const string& word) |
该函数的逻辑比较简单,基于当前字符在它的children映射表中找子节点就可以了。函数的时间复杂度为 O(n),其中 n是输入单词的长度。也就是说,查询操作的时间与输入单词的长度成正比,而与字典树中存储的单词总数无关,这体现了字典树在字符串查询方面的高效性。
3.5 测试
1 | int main() |
程序输出的结果如下:
1 | 前序遍历字典树: |





















