二叉树以及它的形态、性质、存储结构和遍历

二叉树以及它的形态、性质、存储结构和遍历
苏丙榅1. 二叉树
二叉树是一种树形数据结构,其中每个节点最多有两个子节点,分别称为左子节点和右子节点。二叉树由一个根节点和两棵互不相交的子树组成,这两棵子树分别称为根的左子树和右子树。二叉树的定义可以递归地描述:二叉树是一个有限的节点集合,这个集合可以是空集(即没有节点),或者由一个根节点和两棵互不相交的二叉树组成。

1.1 二叉树的特点和形态
二叉树有三个特点依次是:
每个节点最多有两棵子树,所以二叉树中不存在度大于2的节点- 左子树和右子树是有顺序的,次序不能颠倒,也就是说二叉树是有序树
- 即使树中某节点只有一棵子树,也要区分它是左子树还是右子树
基于以上描述,我们对二叉树的形态做了归纳,一共有五种形态,分别是:
- 空二叉树
- 只有一个根节点
- 根节点只有左子树
- 根节点只有右子树
- 根节点既有左子树,又有右子树
以上五种形态应该是比较容易理解的,如果加大难度,大家可以思考一下,如果是有三个节点的二叉树,它一共有几种形态呢?

是的,一共有五种形态,上图中第一种和第二种二叉树比较特殊,它们只有左子树或者只有右子树,和线性表已经无异了。
1.2 特殊的二叉树
斜树
斜树顾名思义一定要是斜的,它一共有两种形态,就是上图中的1和2。
- 所有节点都只有左子树的二叉树叫左斜树
- 所有节点都只有右子树的二叉树叫右斜树
斜树有很明显的特点,就是每一层都只有一个节点,节点的个数与二叉树的深度相同。
通过上图可以看到,不论是左斜树还是右斜树和线性表的的结构是完全相同的,我们可以这样理解:线性表结构是树的一种极特殊的表现形式。
满二叉树
满二叉树就是一棵完美的二叉树,也就是在一颗二叉树中所有分支节点都存在左子树和右子树,并且所有的叶子都在同一层。

上图为大家展示的就是一棵满二叉树。满二叉树有三个特点:
- 叶子节点只能出现在最下层
- 所有的非叶子节点的度一定都是 2
- 在同样深度的二叉树中,满二叉树的节点个数最多,叶子数量最多
完全二叉树
完全二叉树是满二叉树的简配版本,对于深度为k的二叉树,如果其节点个数为n,且每个节点都与深度为k的满二叉树中编号从1到n的节点一一对应,那么这棵二叉树就是完全二叉树。

具体来说,完全二叉树除了最后一层外,每一层上的节点数都达到了最大值,而在最后一层上,节点是连续缺少的,也就是只缺少右边的若干节点。满二叉树一定是一棵完全二叉树,但完全二叉树不一定是满二叉树。
对于完全二叉树而言,有以下五个特点:
- 叶子节点只能出现在最下面两层
- 最下层的叶子一定集中在左侧部分连续位置
- 倒数第二层如有叶子节点,一定都在右部连续位置
- 如果节点度为1,那么该节点一定只有左孩子,不存在只有右子树的情况
- 同样节点数的二叉树,完全二叉树深度最小
基于完全二叉树这种结构特点,使得在查找和访问节点时,可以通过简单的数组索引或类似机制快速定位到任何节点,从而提高了数据处理的效率。
2. 二叉树的性质
二叉树有一些需要理解并且记住的特性,以便我们更好的使用它。

性质1:二叉树的第 i 层上至多有 2i-1(i≥1)个节点 。
- 第1层是根节点,只有一个,2i-1 = 20 = 1。
- 第2层最多有两个节点,22-1 = 21 = 2。
- 第3层最多有四个节点,23-1 = 22 = 4。
- 第4层最多有八个节点,24-1 = 23 = 8。
性质2:深度为 k 的二叉树中至多含有 2k-1 个节点(k≥1) 。
- 如果只有1层,只有一个根节点,至多有1个节点,2k-1 = 21-1 = 1
- 如果有2层,最多的节点数为 1+2 = 2k-1 = 22-1 = 3
- 如果有3层,最多的节点数为 1+2+4 = 2k-1 = 23-1 = 7
- 如果有4层,最多的节点数为 1+2+4+8 = 2k-1 = 24-1 = 15
性质3:若在任意一棵二叉树中,叶子节点有 n0 个,度为2的节点有 n2个,则 n0=n2+1 。
- 在上图中度为2的节点数为5,叶子节点数量为6,满足 n0=n2+1
- 在上图中去掉节点L,度为2的节点数为5,叶子节点数量为6,满足 n0=n2+1
- 在上图中去掉节点K、L,度为2的节点数为4,叶子节点数量为5,满足 n0=n2+1
性质4:具有n个节点的完全二叉树的深度为 ⌊log2n⌋+1(⌊ ⌋ 表示向下取整)。
- 如上图所示,完全二叉树有12个节点,深度为:⌊log212⌋+1 = 3+1 = 4
- 如果在上图基础上再增加4个节点,深度为:⌊log216⌋+1 = 4+1 = 5
性质5:若对一棵有 n 个节点的完全二叉树的节点按层序进行编号(从第1层到第 ⌊log2n⌋+1层,每层从左到右),那么,对于编号为i(1≤i≤n)的节点:
- 当
i=1时,该节点为根,它无双亲节点 。 - 当
i>1时,该节点的双亲节点的编号为i/2。- 对于上图而言,编号为
7(G)的节点,其父节点为3(C) - 对于上图而言,编号为
5(E)的节点,其父节点为2(B) - 对于上图而言,编号为
11(K)的节点,其父节点为5(E)
- 对于上图而言,编号为
- 若
2i≤n,则有编号为2i的左节点,否则没有左节点 。- 上图中的
G(7)、H(8)、I(9)、J(10)、K(11)、L(12)乘以2 > n(12),它们没有左节点 - 上图中的
A(1)、B(2)、C(3)、D(4)、E(5)、F(6)乘以2 ≤ n(12),它们有左节点
- 上图中的
- 若
2i+1≤n,则有编号为2i+1的右节点,否则没有右节点。- 上图中的节点F,2*(F)+1 = 13 > n(12),它没有右节点
- 上图中的
A(1)、B(2)、C(3)、D(4)、E(5)乘以2 + 1 < n(12),它们有右节点
- 当
3. 二叉树的存储结构
3.1 顺序存储
二叉树的顺序存储结构就是用一维数组存储二叉树中的节点,并且通过数组是下标来描述节点之间的逻辑关系,比如双亲和孩子的关系,左右兄弟的关系等。下面通过一棵完全二叉树为大家举例说明:

如果从数组的1号位置开始存储数据,二叉树的节点在数组的位置应该是这样的:
| 下标 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 值 | A | B | C | D | E | F | G | H | I | J | K | L |
- 假设父节点位置为 i,左孩子位置为 2i,右孩子位置为 2i+1
- 假设左孩子节点位置为 i,右兄弟位置为 i+1,父节点位置为 i/2
- 假设右孩子节点位置为 i,左兄弟位置为 i-1,父节点位置为 i/2
如果从数组的0号位置开始存储数据,二叉树的节点在数组的位置应该是这样的:
| 下标 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 值 | A | B | C | D | E | F | G | H | I | J | K | L |
- 假设父节点位置为 i,左孩子位置为 2i+1,右孩子位置为 2i+2
- 假设左孩子节点位置为 i,右兄弟位置为 i+1,父节点位置为 (i-1)/2
- 假设右孩子节点位置为 i,左兄弟位置为 i-1,父节点位置为 (i-1)/2
如果存储的二叉树不是完全二叉树,此时在数组中应该如何存储二叉树的节点呢?

在上面这棵二叉树中有很多节点缺失了,为了看起来更直观,我们使用灰色将其画了出来,在存储这棵普通的二叉树的时候有两种方式:
- 将
A、B、C、F、G、L按顺序依次存储到数组中 - 使用完全二叉树的方式来存储这棵普通的二叉树数据
通过认真分析考虑之后,相信大家选择的都是后者,只有通过这种方式才能通过父节点找到左右孩子节点或者通过左右孩子节点找到它们的父节点。
| 下标 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 值 | A | B | C | ^ | ^ | F | G | ^ | ^ | ^ | ^ | L |
通过上面的表可以清晰的看到使用顺序存储的方式存储二叉树会造成内存的浪费,尤其是当二叉树变成一棵右斜树的时候,浪费的内存空间是最多的。所以顺序存储结构一般只用于存储完全二叉树。
3.2 链式存储
既然顺序存储结果有弊端,我们在来看一下链式存储结果能不能弥补这个缺陷。由于二叉树每个节点最多只有两个孩子,所以为每个树节点设计一个数据域和两个指针域,通过这种方式组成的链表我们称其为二叉链表。
1 | struct TreeNode |
data:存储节点数据,可以根据实际需求指定它的类型。
lchild:存储左侧孩子节点的地址。
rchild:存储右侧孩子节点的地址。

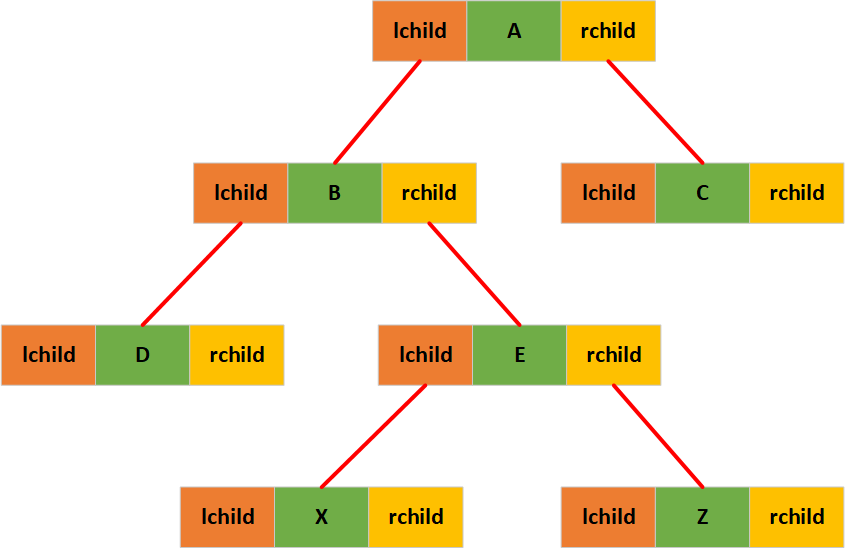
可以看到通过链式存储的方式存储二叉树不存在内存浪费的问题,它适用于任何形式的二叉树。使用二叉链表可以快速的通过父节点访问它的左右孩子节点,但是想要通过孩子节点访问父节点就比较麻烦了,解决方案也比较简单我们可以给链表节点再添加一个指针域,让它指向当前节点的父节点:
1 | struct TreeNode |
- data:存储节点数据,可以根据实际需求指定它的类型。
- lchild:存储左侧孩子节点的地址。
- rchild:存储右侧孩子节点的地址。
- parent:存储双亲节点(父节点)的地址。
通过这种节点组成的链表我们将其称之为三叉链表。
4. 二叉树的遍历
二叉树的遍历是指从根节点出发,按照某种次序依次访问二叉树中的所有节点,使得每个节点被访问一次并且仅被访问一次。
二叉树的次序遍历不同于线性结构,线性结构比较简单通过循序从头到尾进行访问即可。由于树节点之间不存在唯一的前驱和后继关系,在访问一个节点之后,下一个被访问的节点就面临着不同的选择,选择不同,被访问到的节点的顺序也不一样。
由于树的递归定义的,所以树的遍历一般也是通过递归的方式实现,通过递归的方式对树进行遍历一共有三种方式:
- 前序遍历:先访问根节点,然后前序遍历左子树,最后前序遍历右子树
- 中序遍历:中序遍历左子树,然后访问根节点,最后中序遍历右子树
- 后序遍历:后序遍历左子树,然后后序遍历右子树,最后访问根节点
通过三种遍历方式的定义可知,前、中、后其实是相对于根节点而言的,并且二叉树的左子树和右子树的遍历也是递归的,同样遵循前序、中序、后序的规则,在遍历过程中如果树为空,直接返回,递归结束。

在实现遍历函数之前, 我们先把二叉树的节点结构定义出来:
1 | // 定义二叉树节点结构 |
4.1 前序遍历
递归实现
了解了前序遍历的规则之后,我们来分析一下上面这棵二叉树通过前序遍历之后节点的访问顺序是什么?
- 先访问根节点
A - 然后遍历左子树
- 访问根节点
B- 遍历以
B为根节点的左子树,遍历以D为根节点的左子树- 访问根节点
D,访问左子树G,访问右子树H
- 访问根节点
- 遍历以
- 访问根节点
- 最后遍历右子树
- 访问根节点
C- 遍历以
C为根节点的左子树,遍历以E为根节点的左子树- 访问根节点
E,访问左子树nullptr,访问右子树I
- 访问根节点
- 遍历以
C为根节点的右子树,访问根节点F
- 遍历以
- 访问根节点
所以通过前序遍历的方式,树节点的访问顺序为:A、B、D、G、H、C、E、I、F

1 | // 前序递归遍历函数 |
- 首先检查当前节点是否为空,如果为空则直接返回,这是递归的终止条件。
- 若节点不为空,先输出该节点的值,完成对根节点的访问。
- 然后递归调用
preorder函数处理左子树。 - 最后递归调用
preorder函数处理右子树。
非递归实现
关于二叉树的遍历除了使用递归方式,还可以使用非递归方式。我们可以借助栈来完成这个操作,具体步骤如下:
- 初始化:若树为空,直接结束;否则,将根节点压入栈。
- 遍历过程(当栈不为空时,重复以下操作):
- 弹出栈顶节点并访问它。
- 若该节点的右子节点不为空,将右子节点压入栈。
- 若该节点的左子节点不为空,将左子节点压入栈。
- 终止条件:当栈为空时,遍历结束。
因为栈是后进先出的结构,所以先压入右子节点,再压入左子节点,就能保证左子节点先被访问。
1 |
|
终端打印的结果如下:
1 | 前序递归遍历结果: 1 2 4 5 3 |
4.2 中序遍历
递归实现
还是这棵树,如果换成中序遍历,节点的访问顺序就不一样了,我们来根据遍历的规则分析一下:
- 先遍历左子树
- 遍历以
B为根节点的左子树,遍历以D为根节点的左子树- 访问左叶子节点
G,访问根节点D,访问右叶子节点H
- 访问左叶子节点
- 访问根节点的左孩子节点
B
- 遍历以
- 然后访问根节点
A - 最后遍历右子树
- 遍历以
C为根节点的左子树,遍历以E为根节点的左子树- 访问左叶子节点
nullptr,访问根节点E,访问右叶子节点I - 访问根节点
C,遍历右子树,访问根节点F
- 访问左叶子节点
- 遍历以
所以通过中序遍历的方式,二叉树节点的访问顺序为:G、D、H、B、A、E、I、C、F

1 | // 中序递归遍历函数 |
- 首先判断当前节点是否为空,若为空则直接返回,这是递归的终止条件。
- 递归调用
inorder函数处理左子树。 - 输出当前节点的值,完成对根节点的访问。
- 递归调用
inorder函数处理右子树。
非递归实现
通过非递归的方式实现二叉树的中序遍历,还是需要借助数据结构中的栈。遍历的具体步骤如下:
初始化
- 若树为空,直接结束。
- 创建一个空栈,并让辅助指针
current指向根节点。
循环处理(
current不为空或栈不为空):左子树入栈:将
current的所有左子节点依次压入栈,直到current为空。弹出并访问:弹出栈顶节点,访问该节点。
转向右子树:将
current指向弹出节点的右子节点。
1 |
|
终端打印的结果如下:
1 | 中序递归遍历结果: 4 2 5 1 3 |
4.3 后序遍历
递归实现
如果使用遍历的方式遍历这棵树,得到的遍历顺序又会发生变化,其顺序为:
- 先遍历左子树
- 遍历以
B为根节点的左子树,遍历以D为根节点的左子树- 访问左叶子节点
G,访问右叶子节点H,访问根节点D
- 访问左叶子节点
- 遍历以
B为根节点的右子树为 nullptr,访问根节点B
- 遍历以
- 然后遍历右子树
- 遍历以
C为根节点的左子树,遍历以E为根节点的左子树- 访问左叶子节点
nullptr,访问右叶子节点I,访问根节点E - 遍历右子树,访问根节点
F,访问根节点C
- 访问左叶子节点
- 遍历以
- 最后访问根节点
A
所以通过后序遍历的方式,二叉树节点的访问顺序为:G、H、D、B、I、E、F、C、A

1 | void postorder(TreeNode* root) |
- 首先判断当前节点是否为空,若为空则直接返回,这是递归的终止条件。
- 递归调用
postorder函数处理左子树。 - 递归调用
postorder函数处理右子树。 - 输出当前节点的值,完成对根节点的访问。
非递归实现
通过非递归的方式实现二叉树的后序遍历,可以使用单栈标记法也可以使用双栈法。这里给大家讲解双栈法的使用。其核心思想如下:
- 用 栈1 按 根 → 左 → 右 顺序压入节点。
- 将 栈1 弹出的节点压入 栈2,最终 栈2 的出栈顺序即为 左 → 右 → 根(后序)。
具体步骤:
- 根节点压入栈1。
- 循环弹出栈1,依次压入其左子节点、右子节点到栈1。
- 将弹出的节点压入栈2。
- 最终依次弹出栈2的节点并访问。
1 |
|
终端打印的结果如下:
1 | 后序递归遍历结果: 4 5 2 3 1 |
4.4 层序遍历
二叉树的层序遍历是一种广度优先搜索(BFS)的应用,它按照从上到下、从左到右的顺序依次访问二叉树中的每个节点。层序遍历在很多实际场景中都有应用,比如按层处理树状结构的数据、计算树的宽度等。
层序遍历通常借助队列(Queue)这一数据结构来实现。具体步骤如下:
- 初始化:创建一个队列,并将根节点入队列。
- 循环处理:当队列不为空时,执行以下操作:
- 从队列中取出一个节点。
- 访问该节点(比如打印节点的值)。
- 如果该节点有左子节点,将左子节点入队列。
- 如果该节点有右子节点,将右子节点入队列。
- 结束条件:当队列为空时,遍历结束。
1 |
|
终端输出的结果如下:
1 | 层序遍历结果: |
5. 二叉树的创建
5.1 直接构建二叉树
想要构建一棵二叉树最简单的方式就是创建若干个节点,然后按照父子、兄弟关系把它们通过指针连接到一起,代码如下:
1 | int main() |
这种创建二叉树的方法特点是简单,但是不够灵活。
5.2 通过终端输入构建二叉树
如果想要灵活地创建出一个二叉树,可以让用户通过终端输入的方式指定出节点的值以及节点和节点之间的关系,但是有一个细节需要进行处理,就是某些节点没有左孩子或者右孩子。因此,我们可以做这样的一个约定:如果节点的左孩子或者右孩子为空,那么在输入的时候就使用 # 来表示。

准备工作做好之后,我们就可以生成一棵二叉树了,假设二叉树的节点值是一个字符,对应的代码实现如下:
1 | void createPreOrderTree(TreeNode** root) |
上面的代码中是通过先序的方式创建了一棵二叉树,即:先创建根节点,然后创建左子树,最后创建右子树。
如果想要通过中序或者后序的方式创建一棵二叉树,其实也非常简单,只需要对代码做很小的改动:
1 | void createInOrderTree(TreeNode** root) |
现在我们已经可以根据意愿创建出一棵属于自己的二叉树,接下来就是对其进行遍历了。
通过上面的三种递归遍历方式可以看到,函数体内部的代码是极其相似的,只是访问根节点的时机不同罢了,左右子树都是先遍历左子树再遍历右子树,对于子树的遍历也是相同的规则,因此使用递归是遍历二叉树最简单的一种处理方式。
5.3 释放树节点
因为在上面的代码中二叉树的节点是动态创建的,所以在程序的最后还需要释放节点资源,关于释放的顺序应该是先释放子节点然后释放父节点,所以对应的遍历方式应该是后序遍历。最后,基于这种方式我们就可以通过递归的方式释放整棵二叉树。
对应的代码如下:
1 | void freeTree(TreeNode* root) |
最后再次给大家强调一下,不论是使用先序遍历、中序遍历还是后序遍历的方式创建二叉树,在释放资源的时候一定使用的是后续遍历的方式,也就是从下往上,这一点相信大家能够想明白。




















