并查集

并查集
苏丙榅1. 并查集概述
并查集(Union-Find),又称不相交集合(Disjoint Set Union, DSU),是一种用于处理不相交集合的合并与查询问题的数据结构。它支持两种主要操作:
- 查找(Find):确定一个元素属于哪个集合。
- 合并(Union):将两个不同的集合合并成一个集合。
并查集常见的存储方式是使用数组来模拟树结构,利用数组存储每个元素的父节点信息。数组的下标对应元素编号,数组中存储的值代表该元素的父节点编号。通过不断查找元素的父节点,最终找到根节点,以此确定元素所属的集合。
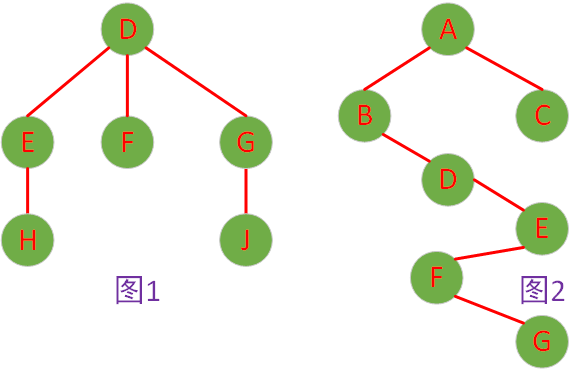
在上图里呈现的是两棵树的结构,而在并查集这种数据结构体系中,这两棵树分别对应着两个集合。从存储实现的角度来看,这两个集合通常会以两个数组的形式来进行表示。
| (图1)数组下标 | 0 | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|---|
| 节点值 | D | E | F | G | H | J |
| 存储的父节点编号 | 0 | 0 | 0 | 0 | 1 | 3 |
| (图2)数组下标 | 0 | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|---|
| 节点值 | A | B | C | D | E | F | G |
| 存储的父节点编号 | 0 | 0 | 0 | 1 | 3 | 4 | 5 |
在并查集所构建的树状结构里,根节点处于一种特殊地位,它不存在父节点。基于此特性,在运用数组来存储并查集信息时,根节点所存储的值为其自身元素在数组中的下标,以此来标识其根节点的独特身份。
1.1 基本概念
在学习并查集之前,有一些相关的概念需要大家先行理解和掌握,具体如下:
- 集合
在并查集里,集合代表一组具有某种关联元素的组合,这些元素在逻辑上被视为一个整体。例如在社交网络场景中,每个集合可以表示一个朋友圈子,圈子里的人通过好友关系相互连接。 - 元素
元素是构成集合的基本单位。以社交网络为例,每个用户就是一个元素,这些元素根据其好友关系被划分到不同的集合中。 - 连通分量
连通分量是指在图中相互连通的元素所构成的最大子集。在并查集的应用中,一个连通分量对应着一个集合。比如在地图连通性问题里,相互可达的地点构成一个连通分量,在并查集中就表示为一个集合。 - 查找
查找操作是指找出某个元素所属的集合。通常通过不断追溯元素的父节点,直到找到根节点,根节点代表该元素所在的集合。例如,在判断社交网络中两个用户是否属于同一个朋友圈子时,就需要对这两个用户进行查找操作,若它们的根节点相同,则属于同一个朋友圈子。 - 合并
合并操作是将两个不同的集合合并成一个集合。当有新的关系建立时,就需要进行合并操作。比如在社交网络中,当两个原本不认识的用户成为好友时,就需要将他们各自所在的朋友圈子合并成一个更大的朋友圈子。
1.2 应用场景
并查集通过高效的路径压缩和按秩合并优化,使其操作的时间复杂度接近常数,适用于处理大规模数据。以下是并查集常见的应用场景:
- 连通性问题
- 社交网络中的好友关系:在社交网络将用户视为节点、好友关系视为边,用并查集判断任意两用户是否处于同一连通分量,有新好友关系时合并对应集合。
- 地图连通性:地图上把地点看作节点、道路看作边,借助并查集可快速判断两地点是否处于同一连通区域、能否相互到达。
- 最小生成树算法
- Kruskal 算法:Kruskal 算法求解加权无向图最小生成树时,用并查集判断加入边的两端点是否属不同集合,不同则合并、相同则跳过以避免成环。
- 网络连接问题
- 局域网设备连接:局域网里将设备视为节点、网络线路视为边,用并查集判断设备是否在同一子网可通信,网络变化时能快速更新连通状态。
- 通信网络故障排查:复杂通信网络中,利用并查集维护连通性信息,通过判断节点连通性变化确定故障可能影响范围。
- 游戏开发
- 地图区域划分:策略游戏中用并查集管理地图不同区域连通性,判断玩家能否在区域间移动及哪些区域属同一势力范围。
- 连连看游戏:连连看游戏中,用并查集维护空白格子(通道)的连通性,快速判断相同图案间有无空白路径以确定能否消除。
2. 查找与合并
2.1 定义并查集类
依据并查集的概念,我们能够轻而易举地完成其对应类的定义:
1 | // 并查集类 |
根据并查集的操作,我们定义了两个功能函数:find(int index)和unionSet(int element1, int element2)分别用于集合数据的搜索以及集合的合并。
在构造函数里,我们对用于存储各节点父节点位置的数组进行了初始化操作。在尚未执行合并操作时,可默认此并查集中存在多棵独立的树,每一个元素都作为当前这棵树的根节点。基于此,当我们在数组中存储每个元素的父节点位置时,只需将其指定为该元素在数组中的下标即可。
2.2 查找
并查集查找规则的核心是:不断寻找元素的父节点,直到找到根节点。因为在并查集中,同一个集合内的所有元素最终都会指向同一个根节点,所以通过不断查找父节点,就可以确定元素所属的集合。具体步骤如下:
- 从要查找的元素开始,检查其存储的父节点信息。
- 如果该元素的父节点就是它本身,说明该元素是根节点,查找结束,返回该元素。
- 如果该元素的父节点不是它本身,就继续查找其父节点的父节点,重复上述过程,直到找到根节点。
根据上面的描述,我们可以使用递归和非递归的方式实现并查集的查找。
基于非递归的方式实现:
1 | int UnionFind::find(int index) |
m_parent是UnionFind类中的一个数组,用于存储每个元素的父节点信息。m_parent[i]表示元素i的父节点的索引。while (index != m_parent[index])是一个循环条件,用于判断当前元素index是否为根节点。如果index不等于m_parent[index],说明index不是根节点,需要继续向上查找其父节点。index = m_parent[index];这行代码将index更新为其父节点的索引,从而继续向上查找。
基于递归的方式实现:
1 | int UnionFind::rfind(int index) |
- 当
index等于m_parent[index]时,说明当前元素index就是根节点,因为根节点的父节点就是其自身。此时,函数直接返回index,递归终止。 - 如果
index不等于m_parent[index],说明当前元素index不是根节点,函数通过递归调用rfind(m_parent[index]),将index的父节点作为新的查找元素,继续进行查找操作,直到找到根节点。
2.3 合并
并查集的合并操作主要用于将两个不同的集合合并成一个集合,合并规则是将一个集合的根节点直接连接到另一个集合的根节点上,不考虑两个集合的规模或树的高度等因素。具体操作步骤如下:
- 查找根节点:对于要合并的两个元素,分别使用查找操作找到它们各自所在集合的根节点。
- 合并集合:将其中一个根节点的父节点设置为另一个根节点,从而将两个集合合并为一个集合。
合并两个集合的代码也非常简单,示例代码如下:
1 | void UnionFind::unionSet(int element1, int element2) |
在执行集合合并操作时,我们实际上并不在意最终合并后的树是以 root1 还是 root2 作为根节点。基于此,合并代码也能够写成 m_parent[root2] = root1 的形式。
2.4 路径压缩
路径压缩是对查找操作的一种优化策略。在查找元素的根节点过程中,将元素直接连接到根节点上,从而减少后续查找操作的时间复杂度。例如,原本元素到根节点的路径较长,经过路径压缩后,元素可以直接指向根节点,下次查找时可以更快地找到根节点。
如下图所示,展示了搜索操作前后树内部结构的变化情况。借助路径压缩技术,树的高度显著降低,使得后续搜索操作的效率得到了明显提升。
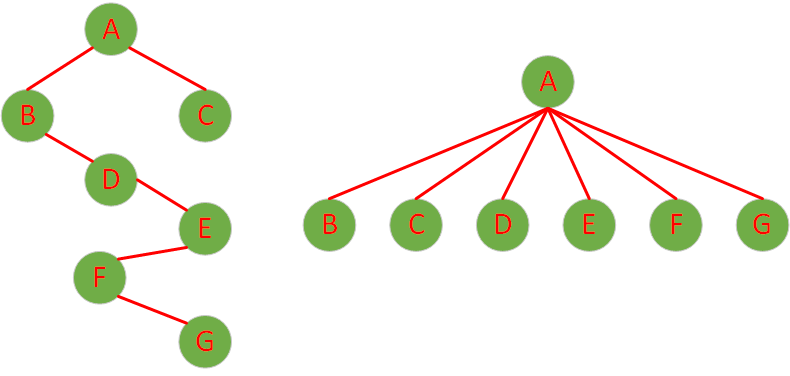
基于递归操作实现的路径压缩查找方法,逻辑简洁且易于理解,具体操作步骤如下:
1 | int UnionFind::rfind(int index) |
if (index != m_parent[index])用于判断当前元素index是否为根节点。如果index不等于m_parent[index],说明当前元素index不是根节点,需要继续向上查找其父节点。m_parent[index] = rfind(m_parent[index]);是路径压缩的关键步骤。通过递归调用rfind(m_parent[index])找到index的根节点,然后将index的父节点直接设置为根节点。这样,在下次查找index或其查找路径上的其他节点时,就可以直接找到根节点,而不需要再经过中间节点,从而减少了查找的时间复杂度。
2.5 按秩合并
按秩合并是合并操作的一种优化方式。秩可以理解为集合的某种“高度”或“规模”。在合并两个集合时,将秩较小的集合合并到秩较大的集合中,这样可以尽量保持树的平衡性,避免树的高度过高,从而提高查找和合并操作的效率。
在此处,我们借助“秩”的概念来记录并查集中树的高度。为此,需要在上述所定义的并查集类里额外添加一个名为 rank 的数组,此数组的下标与并查集节点在数组中的位置一一对应,以此建立起明确的映射关系,方便后续对节点“秩”信息的管理与操作。
1 | class UnionFind |
m_rank数组用于存储当前树的高度。按秩合并的目的是尽量保持树的平衡,避免树的高度增长过快,从而提高查找操作的效率。如果
m_rank[root1] < m_rank[root2],说明root1所在树的高度小于root2所在树的高度,将root1所在的树合并到root2所在的树下面,即将root1的父节点设置为root2。如果
m_rank[root1] > m_rank[root2],则将root2所在的树合并到root1所在的树下面,即将root2的父节点设置为root1。如果
m_rank[root1] == m_rank[root2],任选一个作为新的根节点,这里将root2的父节点设置为root1,并将root1的秩加 1,因为合并后新树的高度增加了 1。

2.6 测试
最后添加一个测试的main()函数:
1 | class UnionFind |
终端输出的结果为:
1 | 元素 0 和 3 在同一个集合中吗? Yes |
当创建 UnionFind uf(10); 时,有 10 个节点,节点编号从 0 到 9,初始状态下每个节点各自构成一个独立的集合,即:
1 | {0}, {1}, {2}, {3}, {4}, {5}, {6}, {7}, {8}, {9} |
uf.unionSet(0, 1);
将节点 0 和节点 1 所在的集合合并,此时集合情况变为:
1 | {0, 1}, {2}, {3}, {4}, {5}, {6}, {7}, {8}, {9} |
uf.unionSet(2, 3);把节点
2和节点3所在的集合合并,集合情况更新为:1
{0, 1}, {2, 3}, {4}, {5}, {6}, {7}, {8}, {9}
uf.unionSet(0, 2);将包含节点
0的集合与包含节点2的集合合并,集合情况变为:1
{0, 1, 2, 3}, {4}, {5}, {6}, {7}, {8}, {9}
uf.unionSet(4, 5);合并节点
4和节点5所在的集合,集合情况更新为:1
{0, 1, 2, 3}, {4, 5}, {6}, {7}, {8}, {9}
uf.unionSet(6, 7);把节点
6和节点7所在的集合合并,集合情况变为:1
{0, 1, 2, 3}, {4, 5}, {6, 7}, {8}, {9}
uf.unionSet(8, 9);合并节点
8和节点9所在的集合,集合情况更新为:1
{0, 1, 2, 3}, {4, 5}, {6, 7}, {8, 9}
uf.unionSet(5, 6);将包含节点
5的集合与包含节点6的集合合并,最终集合情况为:1
{0, 1, 2, 3}, {4, 5, 6, 7}, {8, 9}
经过所有的合并操作后,10 个节点被划分到了 3 个不同的集合中:
- 集合 1:包含节点
0、1、2、3。 - 集合 2:包含节点
4、5、6、7。 - 集合 3:包含节点
8、9。
- 集合 1:包含节点
时间复杂度和空间复杂度分析:
查找操作
同时使用按秩合并和路径压缩可以将查找操作的时间复杂度优化到
O(α(n)),其中α(n)是阿克曼函数的反函数,在实际应用中,α(n)可以看作是一个非常小的常数,几乎可以认为是O(1)。合并操作
合并操作需要先进行两次查找操作,然后根据秩的大小进行合并,因此合并操作的时间复杂度也是
O(α(n))。
综上所述,在使用按秩合并和路径压缩优化的并查集中,查找和合并操作的时间复杂度都接近 O(1),这使得并查集在处理大规模数据时具有很高的效率。
UnionFind 类的空间复杂度主要由 m_parent 和 m_rank 向量决定。因为这两个向量的空间复杂度都是 O(n),所以整个 UnionFind 类的空间复杂度为O(n),其中n是元素的数量。


















